Integrating Apache Kafka Queue With MuleSoft

Introduction
Apache Kafka, an open-source distributed event streaming platform, excels in real-time data pipelines and streaming applications. Its distributed architecture ensures scalability and fault tolerance, employing a publish-subscribe model for decoupled communication. Kafka facilitates log aggregation, event sourcing, and seamless data integration with durability. Its versatility is highlighted in applications such as log analysis, metrics monitoring, and serving as a messaging backbone for microservices. With Kafka Connect enabling external connectivity, organizations leverage its efficiency for building modern, scalable, and reliable event-driven systems in today's dynamic data landscape.
Operations of Apache Kafka
- Batch message listener: A Batch Message Listener in Apache Kafka allows consumers to process messages in batches rather than individually, optimizing efficiency and reducing overhead in scenarios with high message throughput.
- Commit: It refers to acknowledging the successful consumption and processing of messages, ensuring data integrity and recovery in distributed message processing.
- Consume: It refers to the act of retrieving and processing messages from a Kafka topic within a Mule flow.
- Message listener: A Message Listener in Mule 4 with Apache Kafka allows asynchronous reception and processing of Kafka messages in a Mule flow for event-driven integration.
- Publish: It refers to the action of sending messages to a Kafka topic, enabling the integration flow to produce and transmit data to the Kafka messaging system.
- Seek: It refers to setting the consumer offset to a specific position in a Kafka partition for reprocessing messages from that point.
What are Apache Kafka Queues?
In the Apache Kafka Queueing system, messages are saved in a queue fashion. This allows messages in the queue to be ingested by one or more consumers, but one consumer can only consume each message at a time.
What is Kafka Message Queue?
Kafka is a distributed messaging platform that includes message queue and publish-subscribe (“pub-sub”) systems components. It provides publish-subscribe patterns that can scale horizontally across multiple servers while retaining the ability to replay messages
What’s the Difference Between Kafka and RabbitMQ?
Kafka and RabbitMQ are message queue systems you can use in stream processing. A data stream is high-volume, continuous, incremental data that requires high-speed processing. For example, RabbitMQ is a distributed message broker that collects streaming data from multiple sources to route it to different destinations for processing. Apache Kafka is a streaming platform for building real-time data pipelines and streaming applications. Kafka provides a highly scalable, fault-tolerant, and durable messaging system with more capabilities than RabbitMQ.
How To Setup ZooKeeper and Apache Kafka?
- Download ZooKeeper from the link below https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gz
- Download Apache Kafka from the link below https://www.apache.org/dyn/closer.cgi?path=/kafka/2.5.0/kafka_2.12-2.5.0.tgzt
- Now open Kafka config directory. For me it is C: \kafka_2.12-2.5.0\config
- Edit the file “server.properties”.
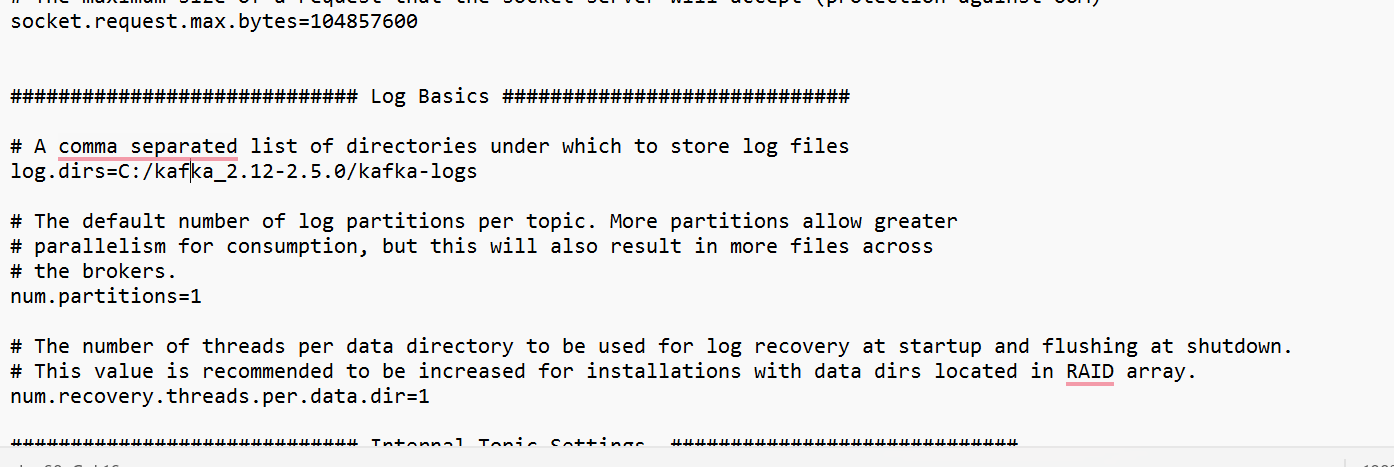
- Find and edit the line “dirs=/tmp/kafka-logs” to “log.dir= C:\kafka_2.13-2.5.0\kafka-logs”
- Create a folder named kafka-logs
- Edit the file “zookeeper.properties”.
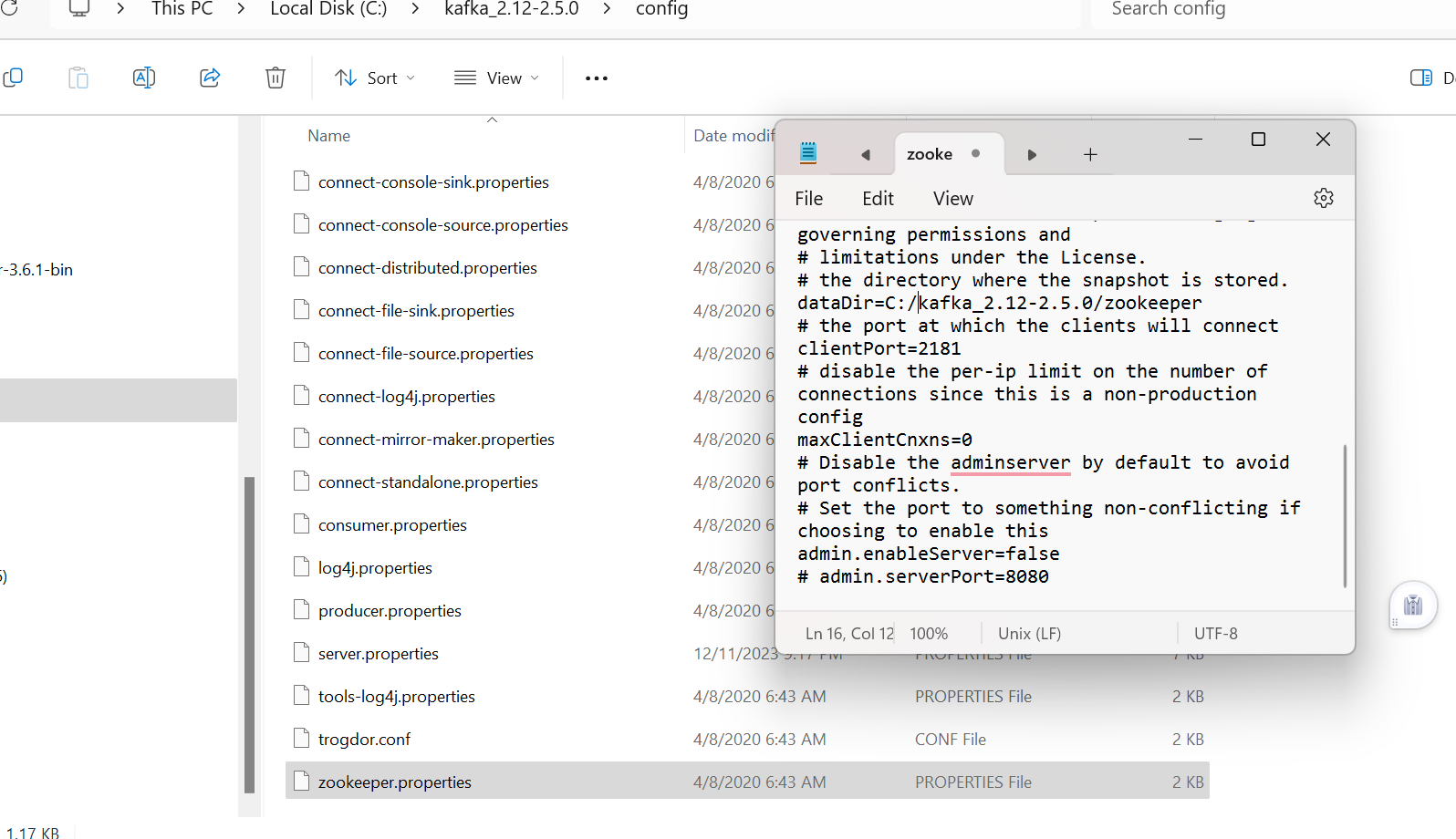
- Find and edit the line“dirs=/tmp/zookeeper” to “log.dir= C:\kafka_2.13-2.5.0\zookeeper”.
Creating Kafka Topic
- Open a new command prompt in the directory C:\kafka_2.13-2.5.0\bin\windows
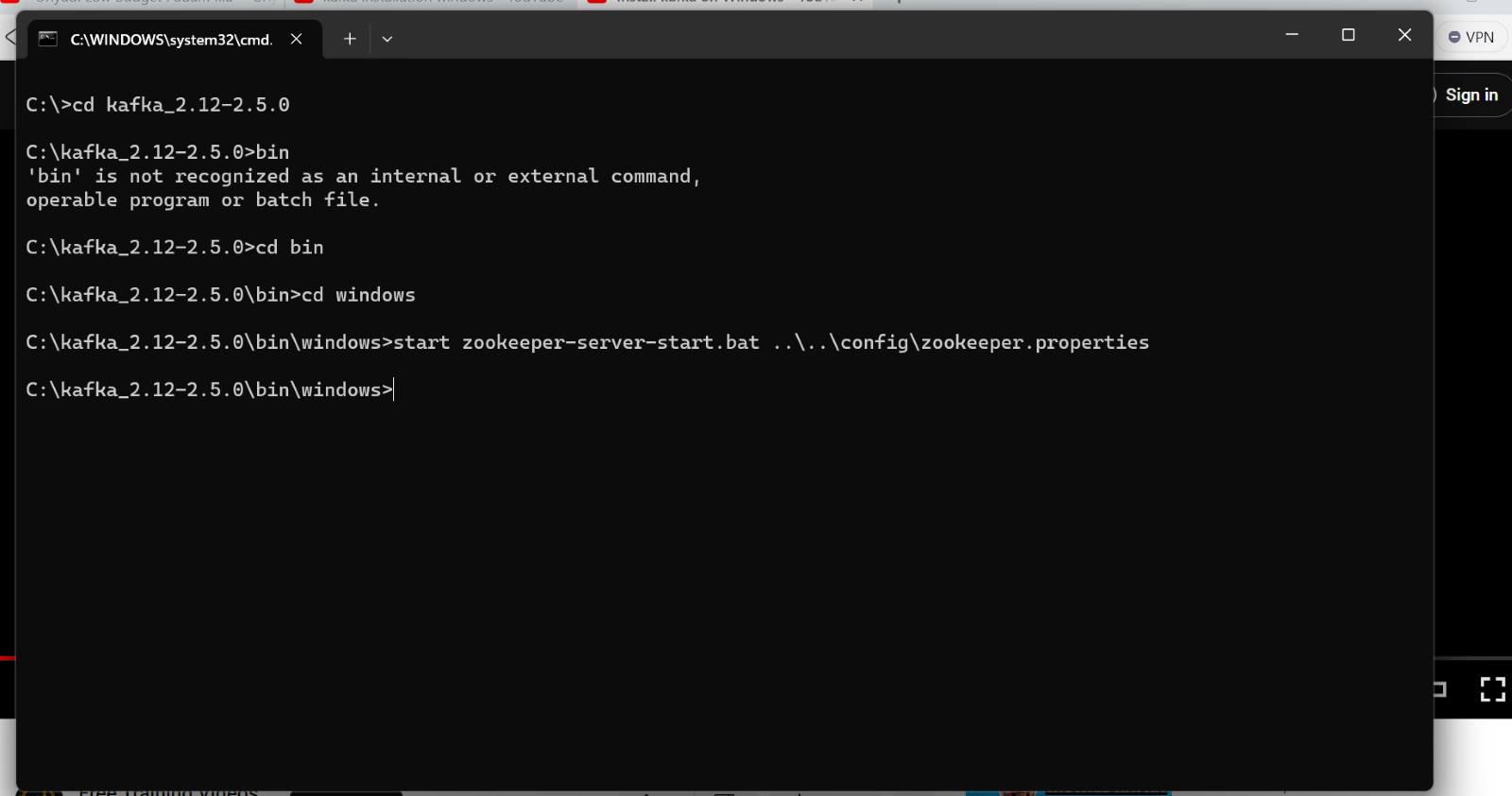
- Type the below command and enter
- You should notice now that the zookeeper is started
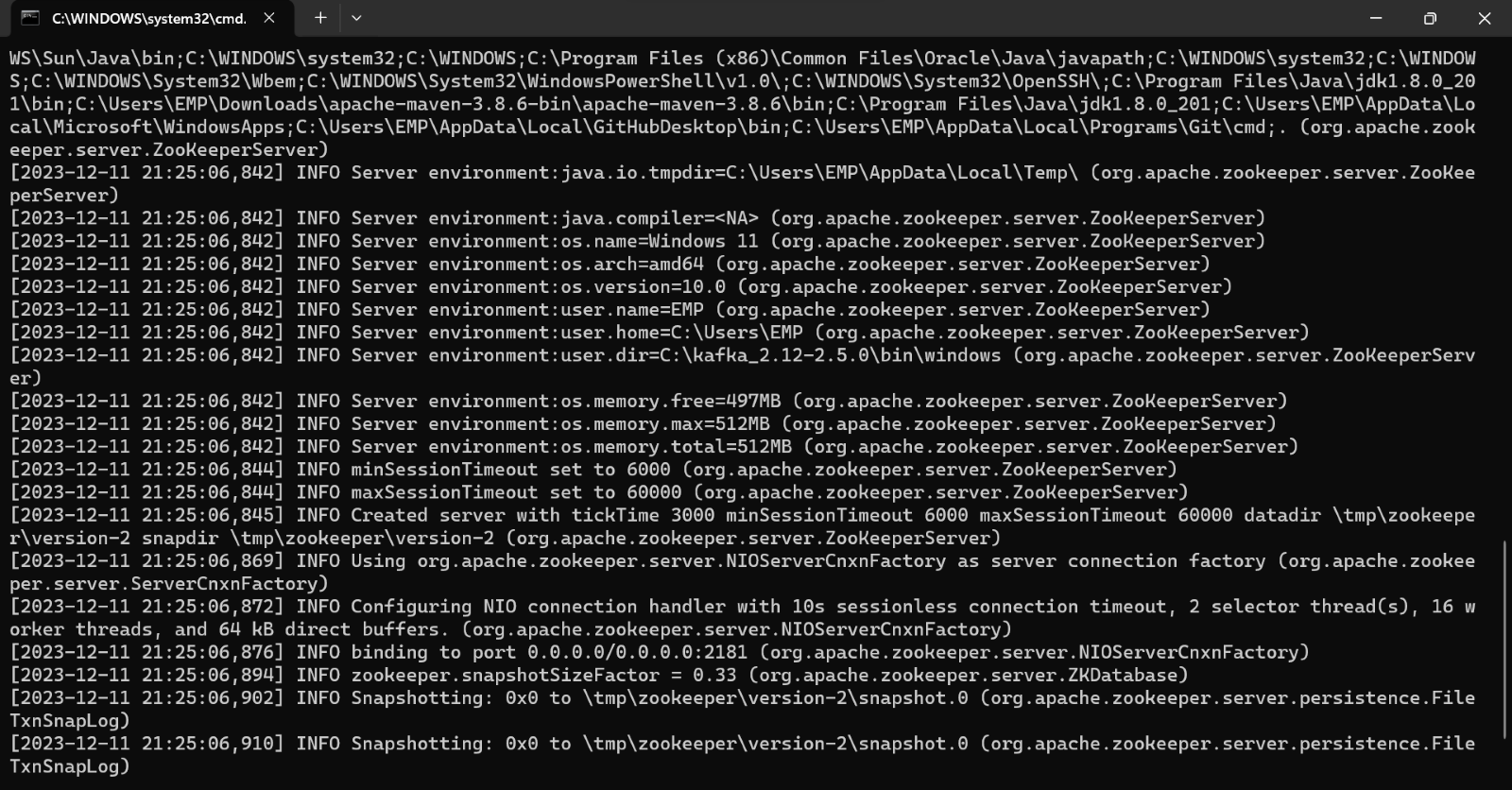
- Type the below command and enter

- You should notice now that the kafka is started
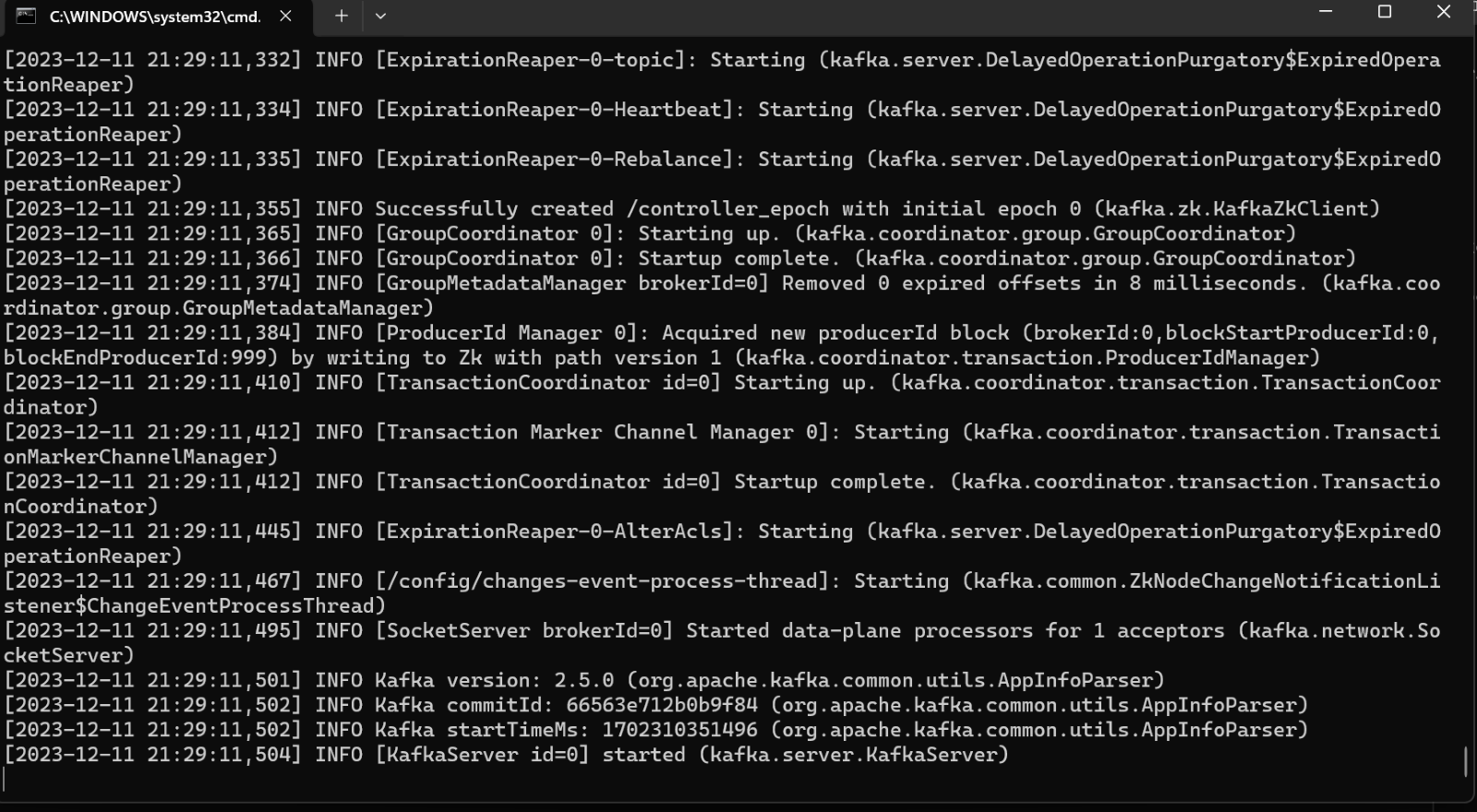
Creating Producer and Consumer to Test Kafka Server
- To connect a producer, type following command
- Open a new command prompt
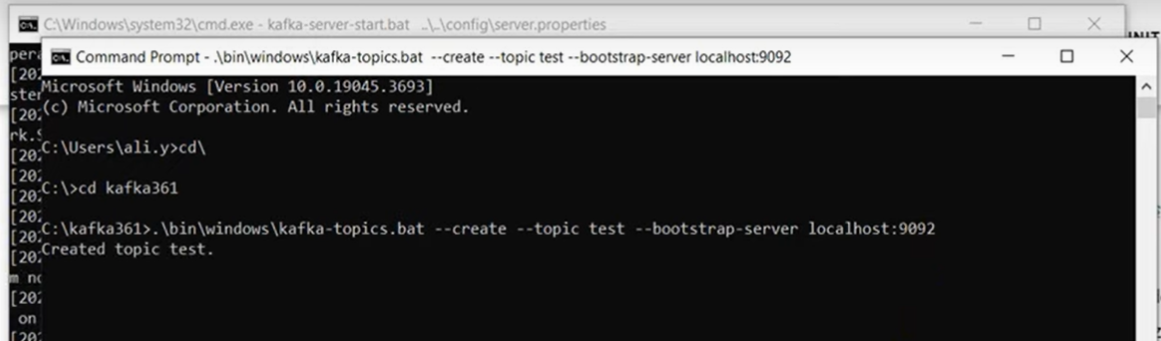
To connect a consumer, type following commands

Producer and consumer are now connected with topic named test.
Steps to create producer flow
- Create a Mule project in Anypoint studio and name it as you like
- Drag and drop flow component from mule palette to mule configuration
- Search and add Apache Kafka module from Anypoint Exchange
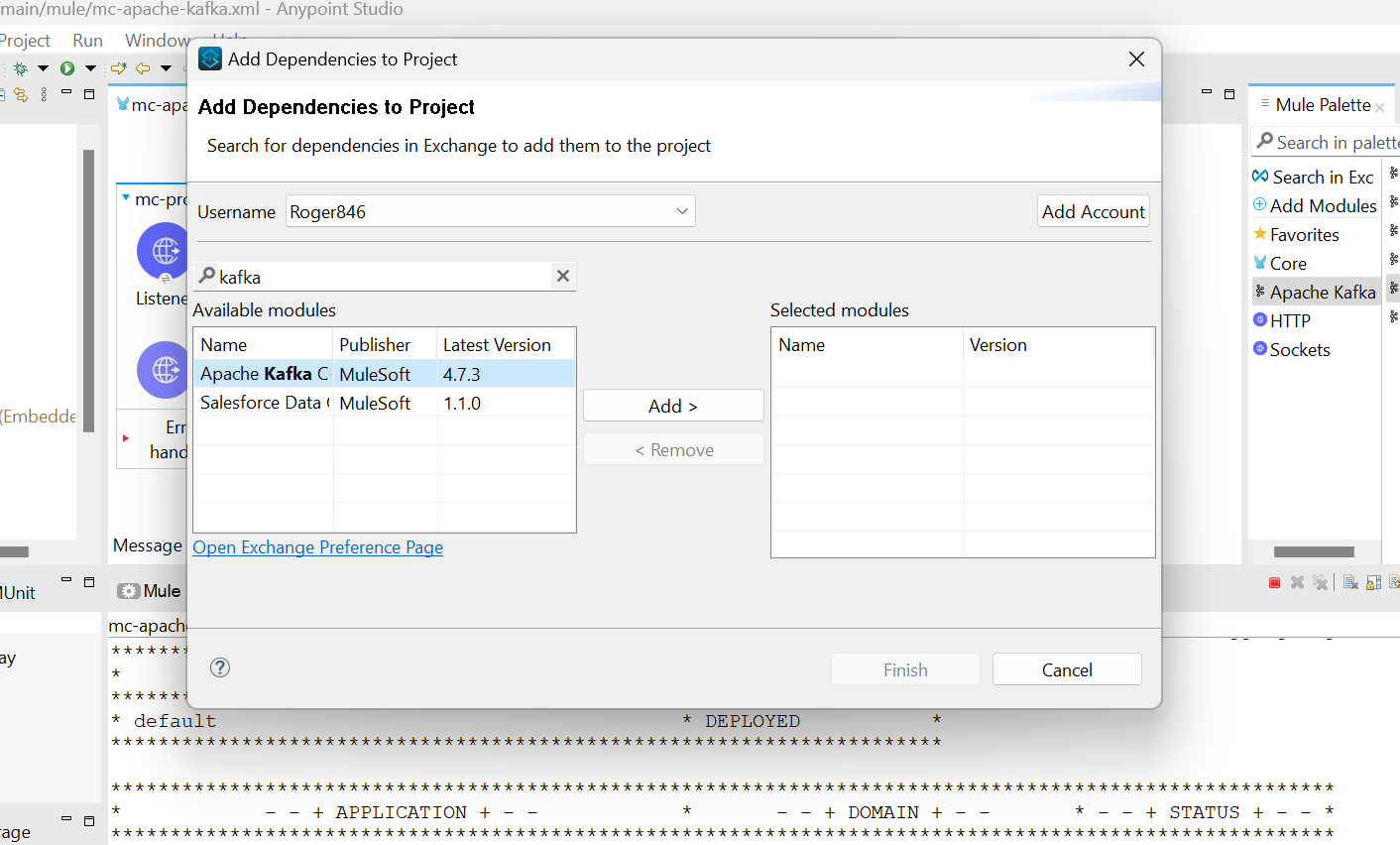
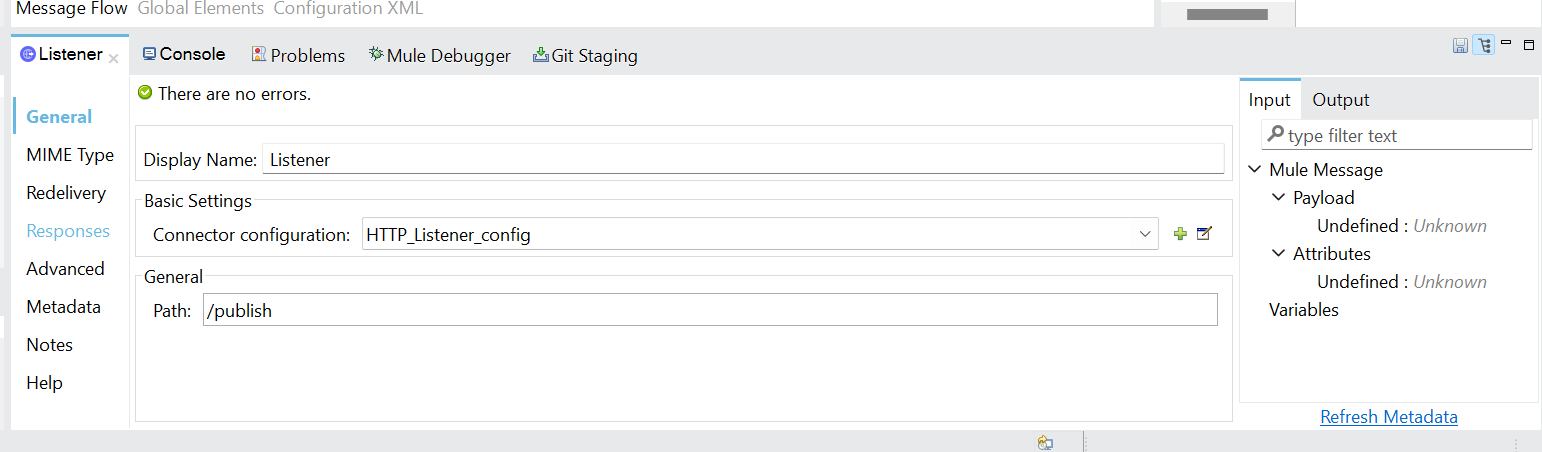
- Now drag HTTP Listener component from mule palette
- Configure HTTP Listener Global configuration with default values and set path as /publish
- Drag publish operation of Apache Kafka component and drop it in mc-producer-flow after HTTP Listener component
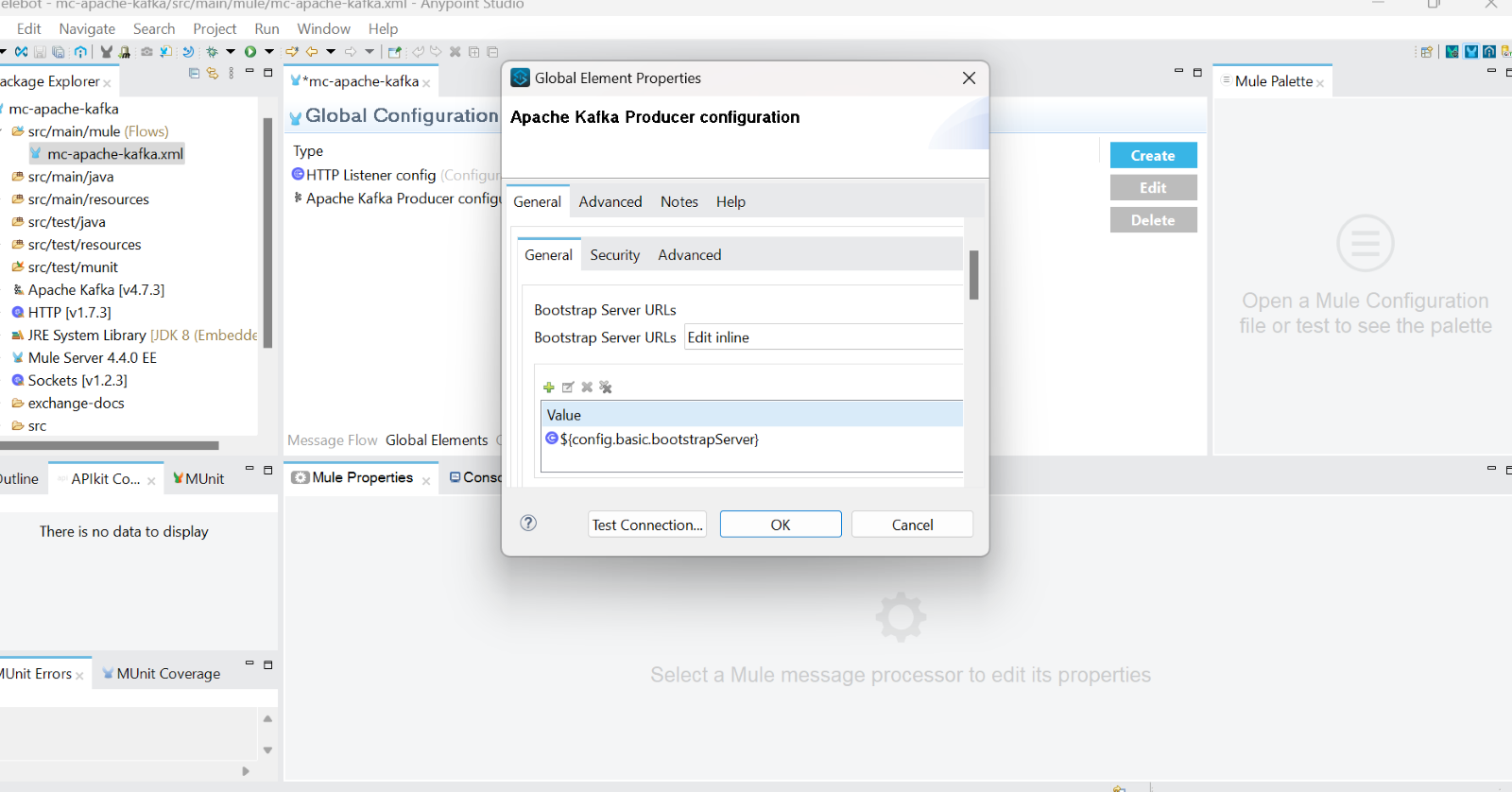
- Add Apache Kafka Producer Configuration for publish operation- value of this property ${config.basic.bootstrapServer} is localhost:9092
- Test connection and click OK
- Now add general settings for Apache Kafka publish operation
For Topic filed, value of this property ${config.topics} is test- In Key field, now() method is used as current date and time.
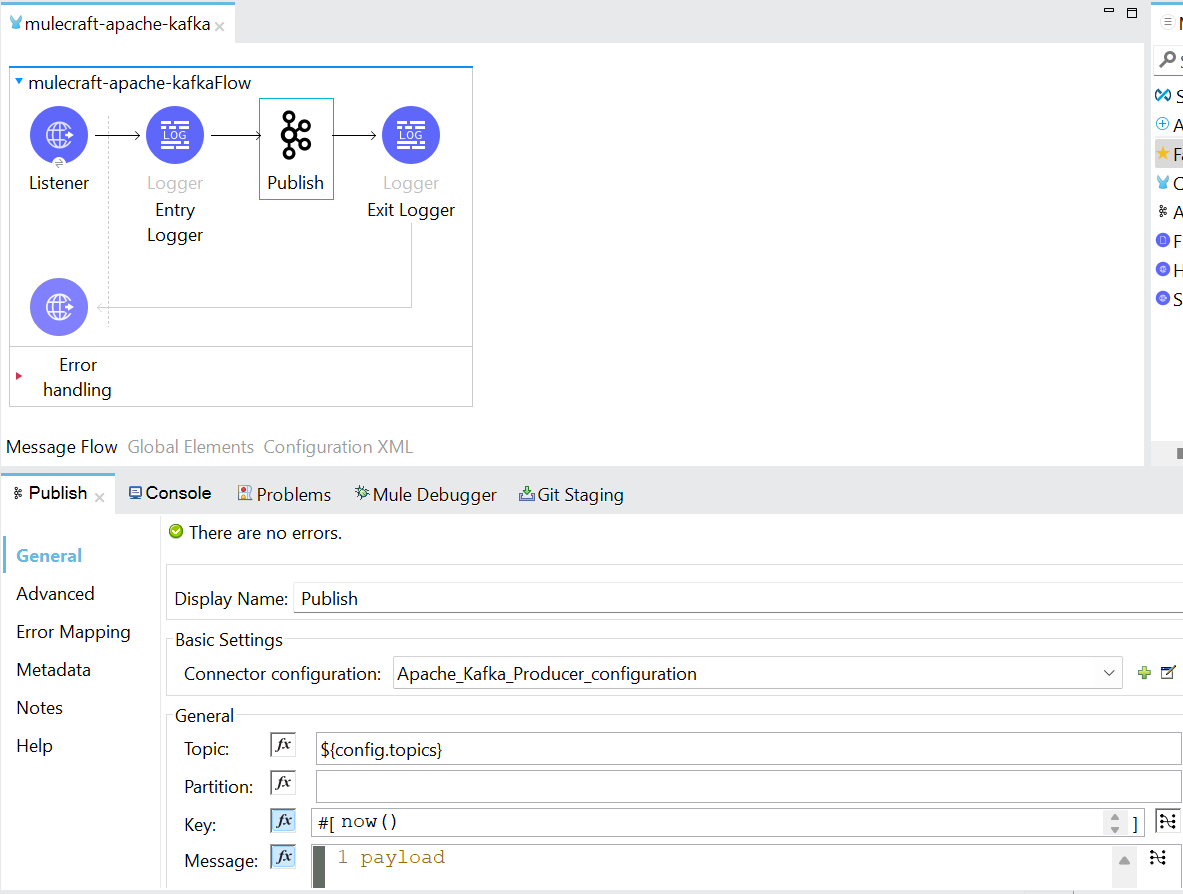
- Now run your mule project
- Open any rest client like postman and hit the URL http://localhost:8081/publish with message body
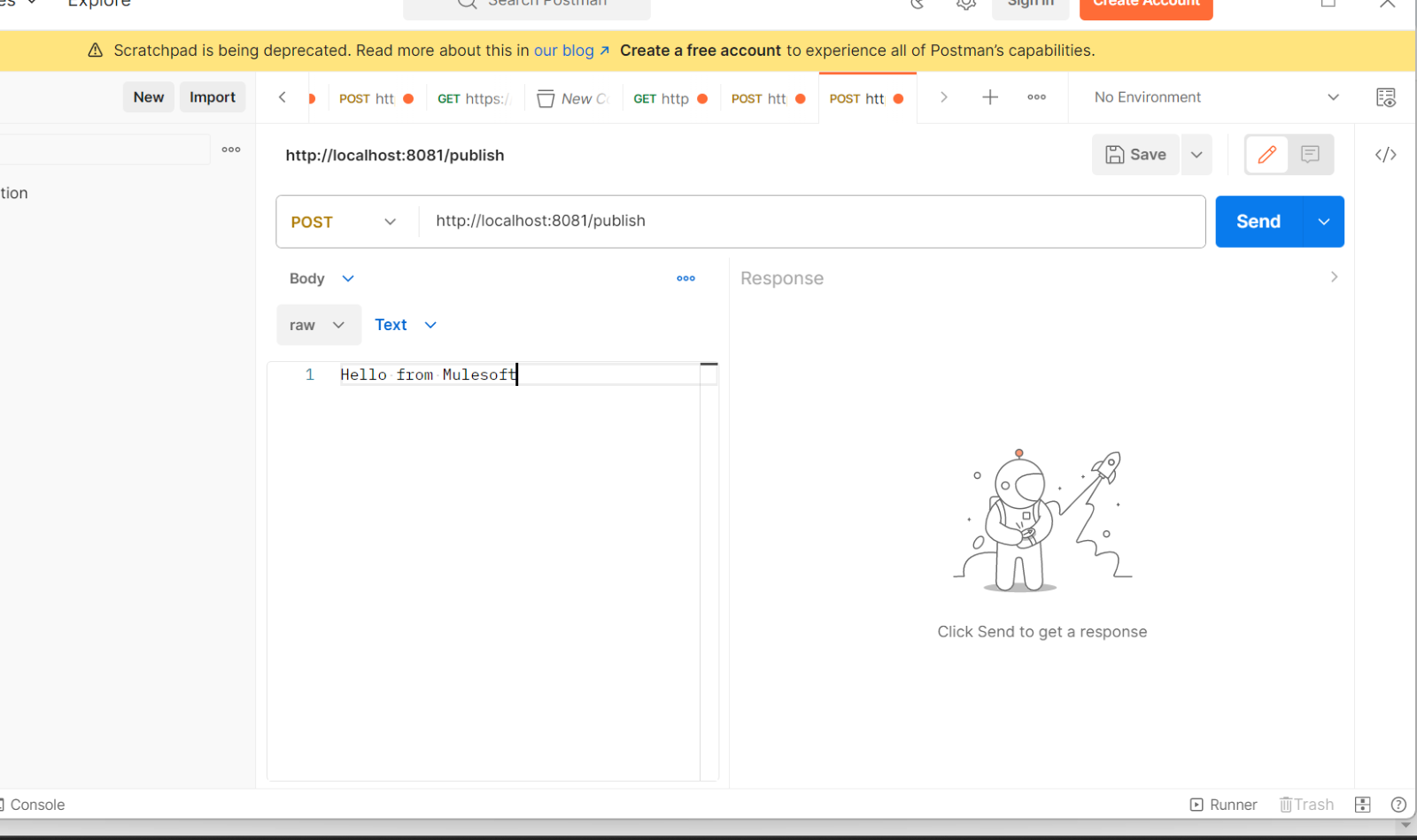
- Now verify in Kafka consumer, the streaming data is received

Steps to create consumer flow
- Drag and drop Flow component to mule configuration and name it as consumer-flow
- Drag Message Listener component of Apache Kafka and drop it to consumer flow
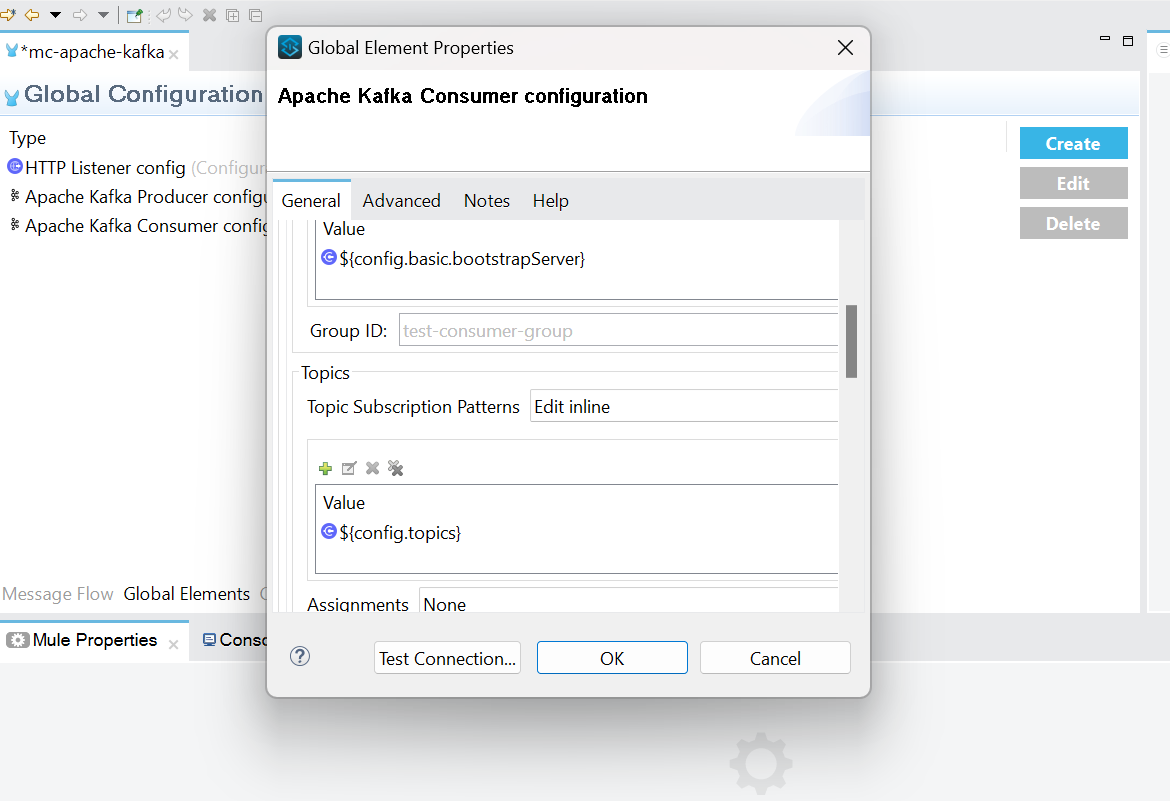
- Add and configure Global Element properties for Apache Kafka consumer- value of property ${config.basic.bootstrapServer} is localhost:9092 - value of property ${config.topics} is test.
- Test connection and click OK.
- Now add and configure write operation of File component right after Message Listener.
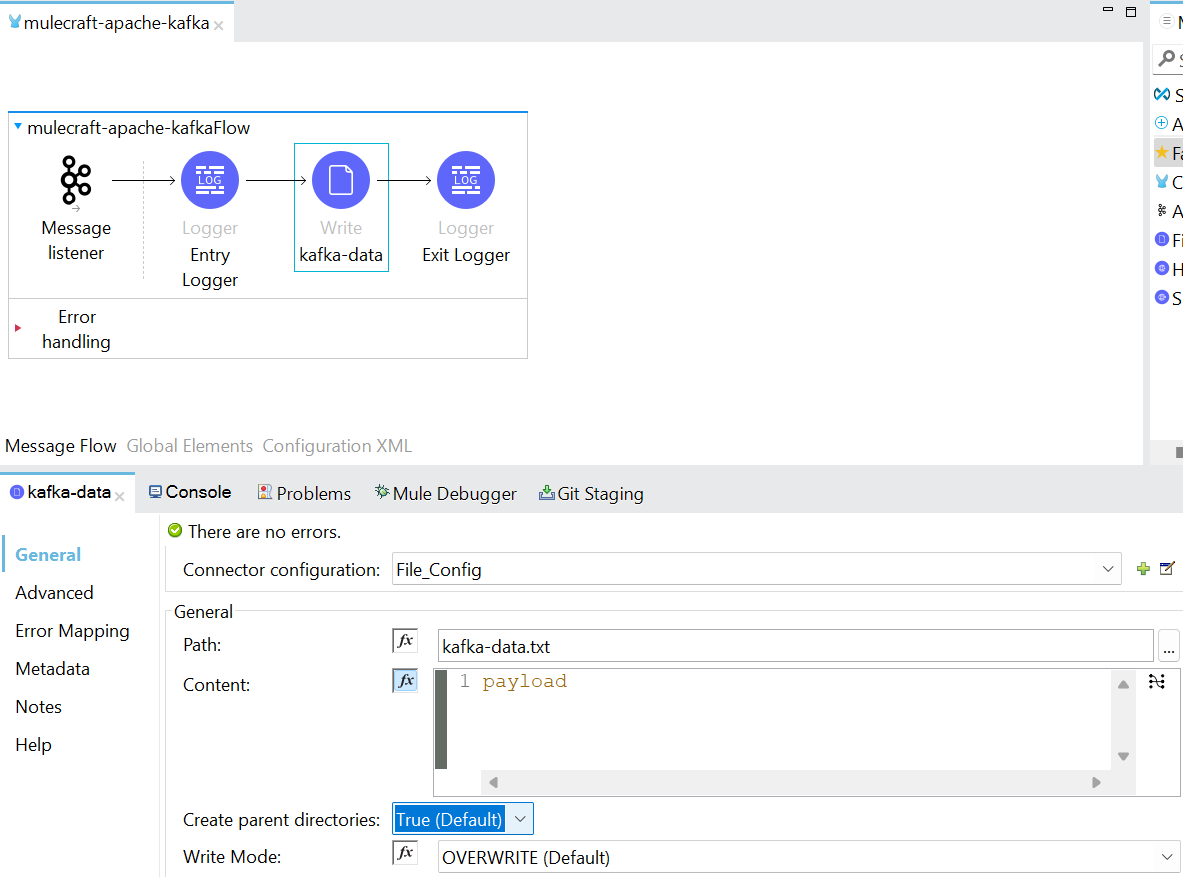
- Run the application and test consumer flow

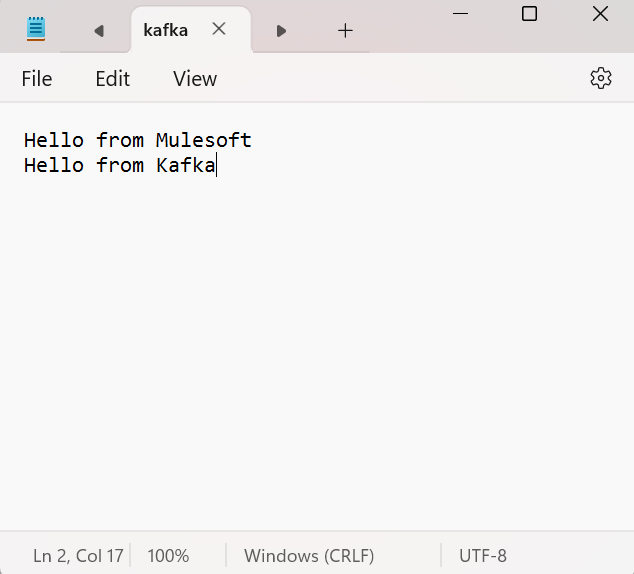
- Write streaming data to Kafka producer
A Powerful Solution
In conclusion, running Apache Kafka in Mule 4 opens up possibilities for building robust, scalable, and real-time data integration solutions. It leverages the strengths of Kafka's messaging system within the Mule runtime, enabling you to create powerful, event-driven applications.